
Author(s)
Dalibor Hlava, Chief AI Officer | Jan Tlaskal, Chief Data Engineer | Amiya Sinha, Chief AI DataFactory Officer | Mauricio Masondo, Head of Growth
Scaling AI in credit has been challenging for banks. Nearly, two-thirds of enterprises worldwide have experimented with AI, but fewer than 10% have scaled it to deliver tangible value. The root causes are lack of domain knowledge, fragmented data, siloed processes, inconsistent governance and generic AI models bolted on top of ageing systems.
We have recently seen an explosion of generic AI agents – large language models wrapped in tools, memory, and orchestration layers – claiming to solve the root causes and scale AI for banks. During experimentation stage, these tools plan, reason, call APIs, and produce impressively fluent answers. But majority struggle to translate these results into measurable bank-wide outcomes as part of scaling.
To deliver tangible results, banks need purpose-built risk domain specialised Digital Officers covering the entire credit chain and performing tasks alongside human credit risk professionals. These Digital Officers have deep risk domain knowledge – learnt from proprietary data training and not from the internet – that allows them to understand context, relationships and end-to-end credit chain processes specific to each bank. They have access to a steady flow of high-quality internal and external data to understand context, not just to generate responses, and governance to ensure they always operate within defined guardrails.
To deep-dive into the root cause issues with generic AI agents we conducted a large-scale benchmarking exercise across generic agents built on frontier LLMs including GPT, Claude, and Gemini — including systems such as Microsoft Copilot and Claude Cowork — covering 200+ credit memos, 200,000+ Q&A evaluations, and 100+ obligors across 30+ global financial institutions (FIs) in North America, Europe, Asia, and Africa. The results clarify why generic agents — even very capable ones — stall at scale in regulated financial environments.
Modern LLMs can already extract information from long documents, perform non-trivial reasoning, explain drivers behind financial movements, and answer complex "why" questions.
Our benchmarking confirms this. On narrow extraction tasks — finding a specific metric breakdown in an annual report, for instance — the best thinking LLMs perform at par with specialised systems. With expert prompting, they can provide deep reasoning on some questions as well.
So why do they still fail in production banking?
Because banks are not optimising for "how smart the answer sounds."
They are optimising for repeatability, auditability, traceability, policy conformance, stability across runs, and security. These dimensions do not improve automatically with better reasoning. In fact, reasoning cannot be optimised independently without degrading the other dimensions.
This is not a theoretical concern. It is now a regulatory one. FINRA's 2026 oversight report included a first-ever section on generative AI, warning broker-dealers to develop procedures specifically targeting hallucinations. The Monetary Authority of Singapore has proposed formal lifecycle controls covering board oversight, AI inventory requirements, and risk materiality assessments for GenAI and AI agents specifically. A Wolters Kluwer survey found that explainability and transparency are the most acute regulatory concern cited by financial institutions (28.4%). And as Fortune recently reported, researchers from Microsoft, Google DeepMind, and Columbia University have identified a "guarantee gap" — the disconnect between AI's probabilistic reliability and the enforceable guarantees institutions need for high-stakes financial tasks.
Treating "better thinking" as the primary lever is a category error in regulated environments.
To understand why reasoning alone falls short, look at what generic agents are actually designed to do.
Generic agents are designed around a human objective — give me the best possible answer to this question. They are excellent at making individuals more productive — analysts, developers, managers. That value is real, and it will continue to grow.
Banks, however, operate on a system objective — produce a decision artefact that is defensible, reproducible, and policy-compliant, every time.
Individual productivity gains do not automatically translate into institutional ROI. Without the right structure, they often increase downstream review, controls, and remediation costs. An analyst who gets a faster first draft from ChatGPT still needs to verify every number, check every citation, and ensure methodology compliance — often spending as much time reviewing the AI output as they would have spent writing it themselves. The data bears this out: MIT's Project NANDA — based on 150+ executive interviews, a survey of 350 employees, and analysis of 300+ publicly disclosed AI deployments — found that 95% of generative AI pilots fail to deliver measurable financial returns, concluding that generic tools "excel for individuals because of their flexibility, but stall in enterprise use since they don't learn from or adapt to workflows."
The infrastructure gap extends beyond workflows: the same Wolters Kluwer survey found that 48% of financial institutions cite data quality as their primary AI readiness challenge, with only 9.5% considering themselves "very prepared" — meaning even a perfect agent would stall on the data it is given.
The question is not whether the model is capable. The question is whether the system it operates within is designed for institutional use.
Our benchmarking revealed consistent weaknesses across all tested generic agents in areas that cannot be solved through prompting alone:
Hallucination resistance. Although users perceive hallucination rates as decreasing — because answers sound increasingly plausible — the real rate in our benchmarking remains around 3–6% of answers containing at least one fabricated artefact. Independent research confirms this: the PHANTOM benchmark (NeurIPS 2025) found that out-of-the-box LLMs "face severe challenges in detecting real-world hallucinations on long-context data" in financial documents. When asked "What is the DSCR of ADNOC?", ChatGPT fabricated a proxy ratio from operating cash flows and finance costs rather than acknowledging the metric was not directly available. The specialised system returned the precise DSCR calculation per the bank's methodology, with full traceability to each component in the source document. In credit, a confidently wrong ratio is worse than no answer at all.
Reliability and consistency. Re-running the same credit memo generation task with generic agents produces structurally different outputs. One run emphasises balance sheet leverage; another leads with income statement trends. Even when each version is "mostly right", this breaks auditability and makes supervisory review impractical at scale. A specialised system produces stable, structurally equivalent outputs across runs because the structure is governed by blueprints, not left to the model's discretion.
Methodology adherence. Generic agents do not have access to an institution's spreading rules, calculation adjustments, or historical analyst overrides. They attempt to use publicly available definitions or internet search results, which often leads to inaccurate figures presented with confidence. When asked about operating lease charges, Copilot misinterpreted the IFRS 16 methodology and presented an incorrect response per the institution's standards. The specialised system correctly identified zero operating lease charges and pointed the analyst to the relevant lease-related metrics with page-level references to the annual report.
Auditability and traceability. Generic agents provide citations — when they do — to entire documents rather than to the precise page, table, or formula. When asked to provide an answer with exact page numbers, Copilot explicitly acknowledged it could not determine page numbers from the extracted text. The specialised system linked quantitative metrics as hyperlinks directly to formula definitions and source locations in the original document.
Security and governance. When a generic agent is used on a confidential credit memo, it typically operates as a user-scoped assistant embedded in an individual’s working context, not as an institutionally governed system service designed around the bank’s control model. In practice, that means the reasoning process runs through a vendor-managed end-user tool and inherits the user’s session, workflow, and local operating context rather than being orchestrated as a centrally governed institutional process. Retention policies, data residency, access controls, and audit logging may exist at the platform level, but they do not by themselves create institution-specific segregation of duties, decision lineage, or workflow governance inside the reasoning process itself. Governance is therefore external to how the agent reasons and acts, not intrinsic to the work structure. For regulated production use, that is a structural gap no amount of prompt engineering can close.
These are not bugs. They are design consequences — and because they are design consequences, they cannot be reliably solved by adding longer prompts, more constraints, or guardrail text. Instructions influence probability, not behavioural certainty. Worse, these weaknesses compound: research from Cognizant AI Lab and UT Austin has shown that LLM performance "deteriorates significantly (and often exponentially) with task horizon length" — meaning multi-step credit workflows are precisely where generic agents are least reliable. Problem adherence cannot rely on persuasion. It requires problem structuring. This is distinct from simply constraining a generic agent with stricter schemas or tool boundaries — an approach that improves reliability but still leaves the model deciding when and how to apply those tools. Problem structuring removes that discretion for known workflows entirely.
This points to a fundamental tradeoff. Reasoning depth and hallucination risk behave like a risk-return frontier: more freedom to reason means more risk of speculation and fabrication; more constraint means more predictability but less depth. Generic agents sit at one end — strong autonomy, high hallucination risk. Rigid template-only systems sit at the other — predictable but brittle. Neither is fit for production banking. The goal is a governed equilibrium that shifts the frontier outward: more reasoning depth without proportionally more hallucination risk.
That is what problem structuring delivers. Not better prompts — a different architecture.
The alternative is not "non-LLM AI". It is a specialised agentic system, purpose-built for credit — effectively a Digital Credit Officer. What is different is not the model. It is the architecture — and specifically, how work is structured before the model ever sees it.
A generic agent receives a task — "generate a credit memo for this obligor" — and improvises. It decides what to extract, in what order, using whatever reasoning strategy it lands on. The result may be impressive. It will also be different every time, uncheckable at scale, and untraceable to source.
A specialised system does the opposite. It starts with problem structuring: decomposing the task into a pipeline of discrete, governed steps — each with defined inputs, outputs, and quality gates. When a task matches a known pattern — a credit memo, a financial spreading, a covenant compliance check — it executes through a blueprint: a curated playbook encoding retrieval, validation, deterministic computation, drafting, verification, and finalisation for that specific task. The LLM operates within this structure — handling judgement, interpretation, exceptions, and escalation — while deterministic processes handle everything that can and should be computed exactly. But the LLM does not decide the pipeline itself.
When a task does not match a known pattern, the system does not pretend otherwise. It falls back to its raw skills — controlled, auditable actions with bounded permissions, typed input/output schemas, and deterministic checks — and marks the output for higher review. The system knows what it knows, and behaves differently when it doesn't.
This distinction — structured pipeline for known work, flagged exploration for unknown work — is what separates a production-grade system from a demonstration.
Decomposition has another consequence that matters enormously in regulated environments: testability. Because each step in the pipeline is discrete, it can be tested, validated, and improved independently — extraction benchmarked against ground truth, calculation verified deterministically, narrative evaluated for grounding and compliance. With a generic agent, the only thing you can evaluate is the final output, and when something is wrong, you cannot isolate where or why. Problem structuring turns quality from something you hope for into something you engineer, step by step.
Specialised systems are slower to build, narrower in scope, and require continuous domain maintenance. That cost is real — and for many institutions, the right path will be adoption rather than in-house development. But the alternative — scaling generic agents with human review as the control layer, or forgoing agentic AI altogether — carries its own compounding cost, one that grows with every workflow it touches.
As underlying models improve — and they will — specialised systems benefit disproportionately: a better LLM operating within a governed pipeline produces better outputs with the same auditability and traceability guarantees. The architecture amplifies model improvements rather than being displaced by them.
The Assessment Framework
To move beyond anecdote, we defined a six-dimension assessment framework covering the full surface area of production-grade credit work:
Dimension | What it measures |
|---|---|
Reasoning depth & freedom | Does the rationale go beyond surface-level observation — with precision, logic, and quality of reasoning? |
Hallucination resistance | Is the response grounded in verifiable truth, or does it contain plausible but fabricated values, metrics, or ratios? |
Reliability & consistency | Are the right metrics selected, with correct values and FI-compliant calculation methodology — consistently across runs? |
Explainability & justifiability | Are the correct drivers identified, with precise and quantified insight — not just surface-level commentary? |
Standardisation | Does the output follow the FI's defined templates, spreading rules, and terminology? |
Auditability & traceability | Can every metric be linked back to its ground-truth source, calculation logic, and full lineage? |
Dimension | What it measures |
|---|---|
Reasoning depth & freedom | Does the rationale go beyond surface-level observation — with precision, logic, and quality of reasoning? |
Hallucination resistance | Is the response grounded in verifiable truth, or does it contain plausible but fabricated values, metrics, or ratios? |
Reliability & consistency | Are the right metrics selected, with correct values and FI-compliant calculation methodology — consistently across runs? |
Explainability & justifiability | Are the correct drivers identified, with precise and quantified insight — not just surface-level commentary? |
Standardisation | Does the output follow the FI's defined templates, spreading rules, and terminology? |
Auditability & traceability | Can every metric be linked back to its ground-truth source, calculation logic, and full lineage? |
Scores were assigned using ground-truth answers, repeat-run testing, and expert review of source grounding, calculation correctness, and adherence to institution-specific methodology. Each dimension was then classified into three zones: green (acceptable from a risk, controls, and governance perspective), amber (not robust enough for consistent compliance — material control weaknesses make policy breach plausible), and red (not acceptable for regulated production — clearly breaches required controls).
We note that security and governance were assessed separately, but because they reflect a structural property of the system architecture — not the quality of individual outputs — all generic agents scored uniformly at the baseline. It is a pass/fail dimension that generic agents currently fail by design.
This framework was applied identically to every solution tested. While benchmark outcomes will vary by workflow and implementation quality, the pattern was consistent across the production-grade credit tasks we tested.
The Pattern
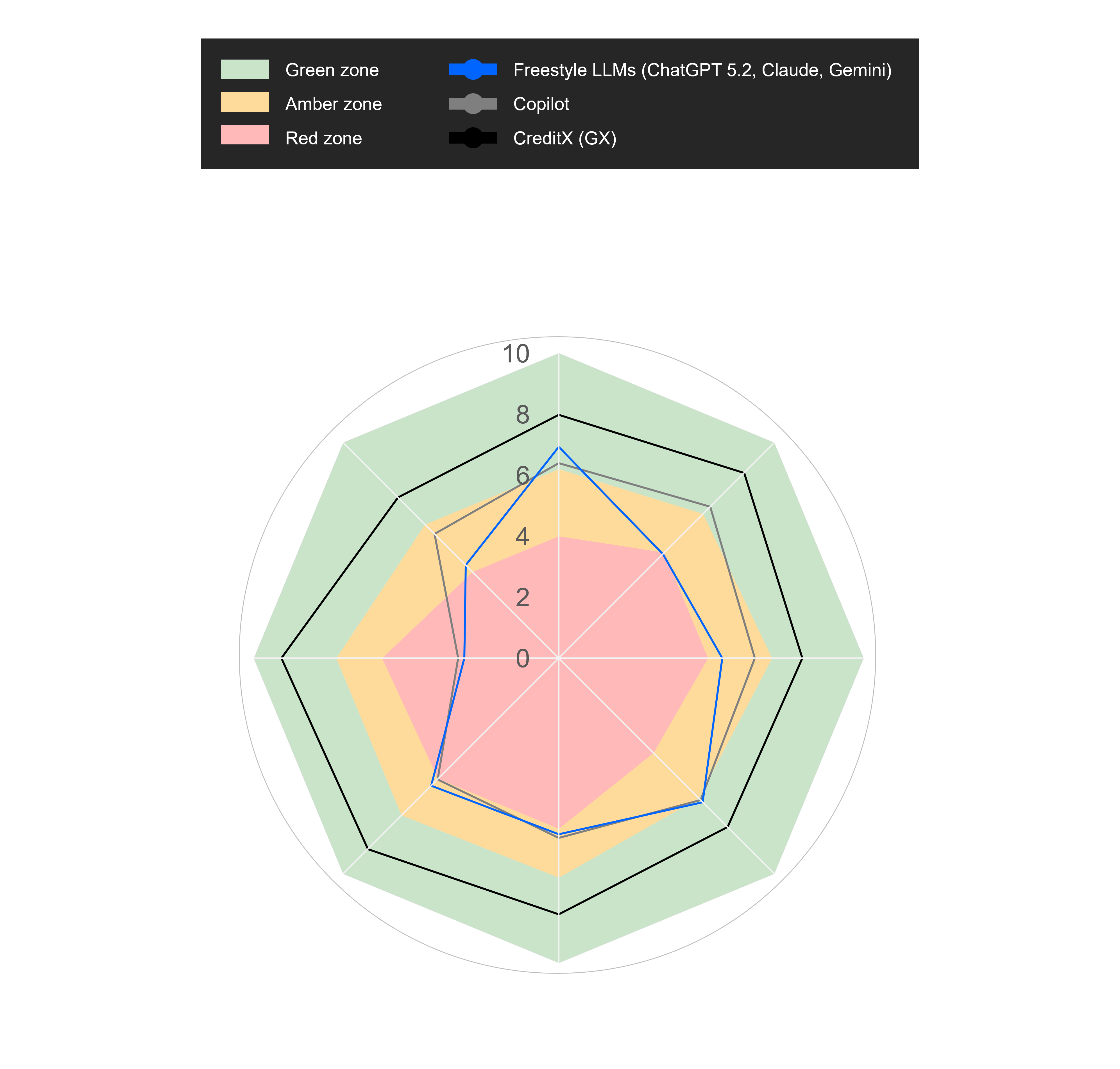
On reasoning depth, the best generic agents performed well — sometimes at par with the specialised system. This is where LLMs shine, and it is not in dispute.
On everything else that matters for production banking, generic agents clustered in red and amber. Hallucination resistance: low. Reliability and consistency: low to moderate. Standardisation: moderate at best. Auditability and traceability: moderate but brittle.
The Digital Credit Officer consistently operated in the green zone across all assessed output dimensions, with security and governance addressed separately at the system architecture level. Not because it uses a better model, but because its architecture enforces what the model alone cannot guarantee.
But Can't Human Review Close the Gap?
We tested this directly: generic agents with human financial analysts reviewing and correcting the outputs. The results were instructive. Human review improved reasoning depth and explainability. But it did not rescue the structural weaknesses — for reasons that become clear when you think about what human review actually does and does not do:
It does not restore reproducibility. Two analysts reviewing the same AI output will correct it differently, producing divergent final versions. It does not create lineage automatically. A human can spot a wrong number, but cannot retroactively build source traceability into an output that was generated without it. It does not make outputs consistent across runs. If the underlying system produces structurally different drafts each time, human review becomes a different editing task each time. And it shifts cost downstream — converting a production problem into a review burden that scales linearly with volume.
Hallucination resistance, standardisation, and auditability remained in amber even with a skilled human in the loop. The instability is in the system, not in the individual output.
The most telling outcome was not a score. It was a behaviour. When generic agents encounter ambiguity or incomplete data, they typically produce a confident-sounding answer. When the Digital Credit Officer encounters the same gap, it refuses to fabricate and tells the analyst exactly what is missing.
In banking, refusal is not a weakness. It is a feature.
Three things determine whether a Digital Officer deployment moves from pilot to production — and the order matters.
Start with the workflow, not the technology. The most common failure pattern is selecting a model and then looking for problems it can solve. Banks that succeed do the opposite: they identify a specific, high-volume credit workflow — annual review memos, financial spreadings, covenant monitoring — where the cost of manual execution is measurable and the methodology is well-defined. A well-scoped workflow gives the system a clear blueprint to encode and a clear baseline to beat.
Fix the data before you fix the model.The Wolters Kluwer survey found that 48% of financial institutions cite data quality as their primary AI readiness challenge. No architecture — generic or specialised — can compensate for fragmented, inconsistent, or inaccessible source data. The institutions that scale fastest are the ones that treat data readiness as a precondition, not a parallel workstream. This means standardising document ingestion, connecting internal data sources, and establishing ground-truth datasets for validation — before the Digital Officer is expected to perform.
Design for adoption, not just accuracy.A system that produces perfect outputs but sits outside the analyst's workflow will not be used. Digital Officers must be embedded in the tools and processes credit professionals already work with — surfacing results where decisions are made, adapting to institution-specific templates and terminology, and giving analysts control over escalation and override. The goal is not to replace the analyst but to remove the mechanical burden so they can focus on judgement. Adoption at scale requires that the system feels like a colleague, not a separate application.
Banks looking to deploy specialised Digital Officers have three options: build, buy or partner. Each can work, but each comes with very different implications for speed, control and long-term value.
Build offers full control over architecture, IP, data and methodology. The system can be designed around the bank’s own credit framework rather than adapted to someone else’s. But that control comes at a price: high cost, long implementation timelines, scarce AI and domain talent requirements, and a real risk of reinventing capabilities already available in the market.
Buy offers speed. Vendors provide ready-made tools, broad functionality and ongoing maintenance, reducing the burden on internal engineering teams. But off-the-shelf products are often black boxes with limited roadmap flexibility and significant vendor dependency. In credit, where rules, calculations, templates and governance are highly institution-specific, generic tooling often struggles to encode the bank’s actual methodology. Faster deployment does not guarantee production fit.
Partner combines the strengths of both. The bank contributes its proprietary workflows, controls and domain standards. The partner contributes a proven platform, specialised expertise, proprietary technology and implementation know-how. This usually delivers faster time to value than building internally, while avoiding the standardisation limits of a pure buy approach. The trade-off is that partnership must be actively managed, and full IP ownership may not sit entirely with the bank.
There is no one-size-fits-all answer. The right choice depends on the institution’s capabilities, urgency and appetite for customisation. But one conclusion is increasingly clear: for regulated production credit work, generic agents are not enough. Success depends on combining domain specificity, strong governance and production-grade technology in the right operating model.
Generic AI will continue to make individuals dramatically more productive. That value is significant and it is here to stay.
But extracting sustained ROI from GenAI at the institutional level — the kind banks need to justify enterprise-wide investment — requires a different approach. A McKinsey/IACPM survey of 44 global banking institutions found that only 12% of North American respondents have deployed any gen AI use case in credit — with hallucination, validation challenges, and regulatory compliance cited as the key barriers. The trajectory is telling: Gartner projects that over 40% of agentic AI projects will be scaled back, restructured, or cancelled by 2027 due to escalating costs, technical debt, or unclear ROI — even as it simultaneously predicts that 40% of enterprise applications will feature task-specific AI agents by end of 2026. The implication is clear: the market is not abandoning AI agents — it is recognising that only specialised ones have a realistic path to production.
The future of AI in banking is not a universal super-agent. It is a landscape of domain specialised digital officers — Digital Credit Officers, Digital Relationship Managers, Digital Risk Officers — each agentic, each domain-grounded, each governed by design.
In banking, the winning systems will not be the ones that sound the smartest. They will be the ones that can be trusted, tested, audited, and defended years after a decision is made. That is why the future belongs not to generic agents, but to specialised digital officers. For banks, the question is not whether to pursue AI transformation at any cost. The more important question is how to deliver short-term success at scale using AI and which approach delivers maximum tangible ROI outcome. Banks cannot judge the merit of their AI investment until they have seen how the system performs at scale being used by financial professionals as part of their day-to-day workflows.
Sources
McKinsey (The State of AI in 2025), McKinsey & Company. (2025, November 5). The state of AI in 2025: Agents, innovation, and transformation. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
FINRA (2026 Annual Regulatory Oversight Report — GenAI Section), Financial Industry Regulatory Authority. (2025, December). 2026 FINRA annual regulatory oversight report: GenAI — Continuing and emerging trends. https://www.finra.org/rules-guidance/guidance/reports/2026-finra-annual-regulatory-oversight-report/gen-ai
MAS (Proposed Guidelines on AI Risk Management for FIs), Monetary Authority of Singapore. (2025, November 13). Consultation paper on proposed guidelines on artificial intelligence risk management for financial institutions. https://www.mas.gov.sg/publications/consultations/2025/consultation-paper-on-guidelines-on-artificial-intelligence-risk-management
Wolters Kluwer (Q1 2026 Banking Compliance AI Trend Report), Wolters Kluwer Financial & Corporate Compliance. (2026, February). Q1 2026: Banking compliance AI trend report. https://www.wolterskluwer.com/en/expert-insights/wolters-kluwer-q1-2026-banking-compliance-ai-trend-report
Fortune (AI agent hallucinates with your money), Lichtenberg, N. (2026, April 8). What do you do when your AI agent hallucinates with your money? Fortune. https://fortune.com/2026/04/08/agent-hallucinations-protocol-money-financial-system-economy/
PHANTOM (NeurIPS 2025), Ji, L., Seyler, D., Kaur, G., Hegde, M., Dasgupta, K., & Xiang, B. (2025). PHANTOM: A benchmark for hallucination detection in financial long-context QA. NeurIPS 2025 Datasets and Benchmarks Track. https://openreview.net/forum?id=5YQAo0S3Hm
MAKER / Million-Step LLM Task (Cognizant AI Lab / UT Austin), Meyerson, E., Paolo, G., Dailey, R., Shahrzad, H., Francon, O., Hayes, C. F., Qiu, X., Hodjat, B., & Miikkulainen, R. (2025, November 12). Solving a million-step LLM task with zero errors (arXiv:2511.09030). Cognizant AI Lab & UT Austin. https://arxiv.org/abs/2511.09030
MIT NANDA / GenAI Divide (primary source, with Fortune coverage), MIT Project NANDA. (2025, July). The GenAI divide: State of AI in business 2025. MIT Media Lab.
Fortune coverage: Fortune Editors. (2025, August 18). MIT report: 95% of generative AI pilots at companies are failing. Fortune. https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/
McKinsey / IACPM (Banking on Gen AI in the Credit Business),McKinsey & Company and International Association of Credit Portfolio Managers. (2025, July 8). Banking on gen AI in the credit business: The route to value creation. https://www.mckinsey.com/capabilities/risk-and-resilience/our-insights/banking-on-gen-ai-in-the-credit-business-the-route-to-value-creation
Gartner (40% of enterprise apps), Gartner, Inc. (2025, August 26). Gartner predicts 40% of enterprise apps will feature task-specific AI agents by 2026, up from less than 5% in 2025 [Press release]. https://www.gartner.com/en/newsroom/press-releases/2025-08-26-gartner-predicts-40-percent-of-enterprise-apps-will-feature-task-specific-ai-agents-by-2026-up-from-less-than-5-percent-in-2025